- NumPy - Home
- NumPy - Introduction
- NumPy - Environment
- NumPy Arrays
- NumPy - Ndarray Object
- NumPy - Data Types
- NumPy Creating and Manipulating Arrays
- NumPy - Array Creation Routines
- NumPy - Array Manipulation
- NumPy - Array from Existing Data
- NumPy - Array From Numerical Ranges
- NumPy - Iterating Over Array
- NumPy - Reshaping Arrays
- NumPy - Concatenating Arrays
- NumPy - Stacking Arrays
- NumPy - Splitting Arrays
- NumPy - Flattening Arrays
- NumPy - Transposing Arrays
- NumPy Indexing & Slicing
- NumPy - Indexing & Slicing
- NumPy - Indexing
- NumPy - Slicing
- NumPy - Advanced Indexing
- NumPy - Fancy Indexing
- NumPy - Field Access
- NumPy - Slicing with Boolean Arrays
- NumPy Array Attributes & Operations
- NumPy - Array Attributes
- NumPy - Array Shape
- NumPy - Array Size
- NumPy - Array Strides
- NumPy - Array Itemsize
- NumPy - Broadcasting
- NumPy - Arithmetic Operations
- NumPy - Array Addition
- NumPy - Array Subtraction
- NumPy - Array Multiplication
- NumPy - Array Division
- NumPy Advanced Array Operations
- NumPy - Swapping Axes of Arrays
- NumPy - Byte Swapping
- NumPy - Copies & Views
- NumPy - Element-wise Array Comparisons
- NumPy - Filtering Arrays
- NumPy - Joining Arrays
- NumPy - Sort, Search & Counting Functions
- NumPy - Searching Arrays
- NumPy - Union of Arrays
- NumPy - Finding Unique Rows
- NumPy - Creating Datetime Arrays
- NumPy - Binary Operators
- NumPy - String Functions
- NumPy - Matrix Library
- NumPy - Linear Algebra
- NumPy - Matplotlib
- NumPy - Histogram Using Matplotlib
- NumPy Sorting and Advanced Manipulation
- NumPy - Sorting Arrays
- NumPy - Sorting along an axis
- NumPy - Sorting with Fancy Indexing
- NumPy - Structured Arrays
- NumPy - Creating Structured Arrays
- NumPy - Manipulating Structured Arrays
- NumPy - Record Arrays
- Numpy - Loading Arrays
- Numpy - Saving Arrays
- NumPy - Append Values to an Array
- NumPy - Swap Columns of Array
- NumPy - Insert Axes to an Array
- NumPy Handling Missing Data
- NumPy - Handling Missing Data
- NumPy - Identifying Missing Values
- NumPy - Removing Missing Data
- NumPy - Imputing Missing Data
- NumPy Performance Optimization
- NumPy - Performance Optimization with Arrays
- NumPy - Vectorization with Arrays
- NumPy - Memory Layout of Arrays
- Numpy Linear Algebra
- NumPy - Linear Algebra
- NumPy - Matrix Library
- NumPy - Matrix Addition
- NumPy - Matrix Subtraction
- NumPy - Matrix Multiplication
- NumPy - Element-wise Matrix Operations
- NumPy - Dot Product
- NumPy - Matrix Inversion
- NumPy - Determinant Calculation
- NumPy - Eigenvalues
- NumPy - Eigenvectors
- NumPy - Singular Value Decomposition
- NumPy - Solving Linear Equations
- NumPy - Matrix Norms
- NumPy Element-wise Matrix Operations
- NumPy - Sum
- NumPy - Mean
- NumPy - Median
- NumPy - Min
- NumPy - Max
- NumPy Set Operations
- NumPy - Unique Elements
- NumPy - Intersection
- NumPy - Union
- NumPy - Difference
- NumPy Random Number Generation
- NumPy - Random Generator
- NumPy - Permutations & Shuffling
- NumPy - Uniform distribution
- NumPy - Normal distribution
- NumPy - Binomial distribution
- NumPy - Poisson distribution
- NumPy - Exponential distribution
- NumPy - Rayleigh Distribution
- NumPy - Logistic Distribution
- NumPy - Pareto Distribution
- NumPy - Visualize Distributions With Sea born
- NumPy - Matplotlib
- NumPy - Multinomial Distribution
- NumPy - Chi Square Distribution
- NumPy - Zipf Distribution
- NumPy File Input & Output
- NumPy - I/O with NumPy
- NumPy - Reading Data from Files
- NumPy - Writing Data to Files
- NumPy - File Formats Supported
- NumPy Mathematical Functions
- NumPy - Mathematical Functions
- NumPy - Trigonometric functions
- NumPy - Exponential Functions
- NumPy - Logarithmic Functions
- NumPy - Hyperbolic functions
- NumPy - Rounding functions
- NumPy Fourier Transforms
- NumPy - Discrete Fourier Transform (DFT)
- NumPy - Fast Fourier Transform (FFT)
- NumPy - Inverse Fourier Transform
- NumPy - Fourier Series and Transforms
- NumPy - Signal Processing Applications
- NumPy - Convolution
- NumPy Polynomials
- NumPy - Polynomial Representation
- NumPy - Polynomial Operations
- NumPy - Finding Roots of Polynomials
- NumPy - Evaluating Polynomials
- NumPy Statistics
- NumPy - Statistical Functions
- NumPy - Descriptive Statistics
- NumPy Datetime
- NumPy - Basics of Date and Time
- NumPy - Representing Date & Time
- NumPy - Date & Time Arithmetic
- NumPy - Indexing with Datetime
- NumPy - Time Zone Handling
- NumPy - Time Series Analysis
- NumPy - Working with Time Deltas
- NumPy - Handling Leap Seconds
- NumPy - Vectorized Operations with Datetimes
- NumPy ufunc
- NumPy - ufunc Introduction
- NumPy - Creating Universal Functions (ufunc)
- NumPy - Arithmetic Universal Function (ufunc)
- NumPy - Rounding Decimal ufunc
- NumPy - Logarithmic Universal Function (ufunc)
- NumPy - Summation Universal Function (ufunc)
- NumPy - Product Universal Function (ufunc)
- NumPy - Difference Universal Function (ufunc)
- NumPy - Finding LCM with ufunc
- NumPy - ufunc Finding GCD
- NumPy - ufunc Trigonometric
- NumPy - Hyperbolic ufunc
- NumPy - Set Operations ufunc
- NumPy Useful Resources
- NumPy - Quick Guide
- NumPy - Cheatsheet
- NumPy - Useful Resources
- NumPy - Discussion
- NumPy Compiler
NumPy - Zipf Distribution
What is the Zipf Distribution?
The Zipf Distribution is a discrete probability distribution that describes the frequency of elements ranked in descending order.
It follows the principle that the frequency of an element is inversely proportional to its rank in the frequency table, often seen in natural languages where the most common word appears twice as often as the second most common word, three times as often as the third, and so on.
It is defined by a parameter "s", which determines the skewness of the distribution. Example: The distribution of word frequencies in a large text corpus often follows a Zipf distribution. Mathematically, the probability mass function (PMF) of the Zipf distribution is given by:
P(X = k) = (1 / ks) / H(N, s)
Here, k is the rank, s is the exponent characterizing the distribution, and H(N, s) is the Nth generalized harmonic number, which normalizes the distribution.
Generating Zipf Samples in NumPy
NumPy provides the numpy.random.zipf() function to generate random samples from a Zipf distribution. This function requires two main parameters:
- a: The distribution parameter, also known as the exponent.
- size: The number of samples to generate (optional).
Example: Generating Zipf Samples
The following example generates 10 random samples from a Zipf distribution with an exponent of 2 −
import numpy as np
# Generate Zipf samples
a = 2
samples = np.random.zipf(a, size=10)
print("Generated Zipf samples:", samples)
Following is the output obtained −
Generated Zipf samples: [1 3 1 2 1 1 1 1 2 1]
Properties of the Zipf Distribution
The Zipf distribution has several unique properties that make it useful for modeling real-world phenomena, they are −
- Heavy Tail: The distribution has a heavy tail, meaning a small number of events are very common, while the majority are rare.
- Power Law: The probability of an event is inversely proportional to its rank raised to the power of the exponent.
- Scale-Invariant: The distribution remains the same when the scale of measurement changes.
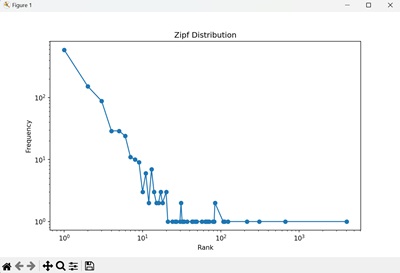
Example: Visualizing Zipf's Law
Let us visualize the Zipf distribution to understand its properties better. We can plot the frequency of occurrences of each rank using Matplotlib −
import numpy as np
import matplotlib.pyplot as plt
# Generate a large number of samples
a = 2
samples = np.random.zipf(a, size=1000)
# Count occurrences of each rank
unique, counts = np.unique(samples, return_counts=True)
# Plot the rank-frequency distribution
plt.figure(figsize=(10, 6))
plt.loglog(unique, counts, marker="o")
plt.title("Zipf Distribution")
plt.xlabel("Rank")
plt.ylabel("Frequency")
plt.show()
We obtained a log-log plot showing the frequency of each rank, demonstrating the heavy tail and power-law nature of the Zipf distribution −
Applications of the Zipf Distribution
The Zipf distribution is used in various fields to model phenomena where a few items are very common, and many items are rare. Common applications are −
- Natural Language Processing (NLP): Modeling word frequencies in a corpus.
- Population Studies: Analyzing city populations and sizes.
- Internet Traffic: Understanding the distribution of web page visits and hits.
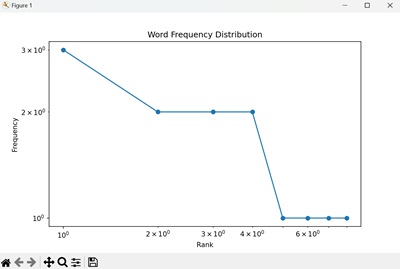
Example: Word Frequency in Text
Suppose we have a text document and want to model the frequency of words using the Zipf distribution −
import matplotlib.pyplot as plt
from collections import Counter
# Sample text
text = "the quick brown fox jumps over the lazy dog the quick brown fox"
# Split text into words
words = text.split()
# Count word frequencies
word_counts = Counter(words)
# Get ranks and frequencies
ranks = range(1, len(word_counts) + 1)
frequencies = [count for word, count in word_counts.most_common()]
# Plot the rank-frequency distribution
plt.figure(figsize=(10, 6))
plt.loglog(ranks, frequencies, marker="o")
plt.title("Word Frequency Distribution")
plt.xlabel("Rank")
plt.ylabel("Frequency")
plt.show()
We obtain a log-log plot showing the frequency of each word rank in the text, following the Zipf distribution −
Estimating Zipf's Exponent
In real-world applications, we often need to estimate the exponent parameter of the Zipf distribution. This can be done using various statistical techniques. One simple method is to fit a line to the log-log plot of rank vs. frequency.
Example: Estimating the Exponent
In the example below, the estimated exponent is close to the actual value (a = 2), demonstrating the accuracy of the estimation method −
import numpy as np
from scipy.stats import linregress
# Generate a large number of samples
a = 2
samples = np.random.zipf(a, size=1000)
# Count occurrences of each rank
unique, counts = np.unique(samples, return_counts=True)
# Perform linear regression on the log-log plot
log_ranks = np.log(unique)
log_counts = np.log(counts)
slope, intercept, r_value, p_value, std_err = linregress(log_ranks, log_counts)
print("Estimated exponent:", -slope)
The output obtained is as shown below −
Estimated exponent: 0.8852106553815038
Simulating Real-World Scenarios
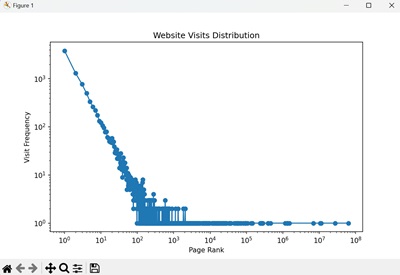
Let us simulate a real-world scenario using the Zipf distribution. Suppose we want to model the distribution of website visits on a popular news site.
Example: Website Visits
We can generate a large number of samples from a Zipf distribution and analyze the distribution of visits to different pages −
import matplotlib.pyplot as plt
import numpy as np
# Generate Zipf samples
a = 1.5
samples = np.random.zipf(a, size=10000)
# Count occurrences of each page visit
unique, counts = np.unique(samples, return_counts=True)
# Plot the rank-frequency distribution
plt.figure(figsize=(10, 6))
plt.loglog(unique, counts, marker="o")
plt.title("Website Visits Distribution")
plt.xlabel("Page Rank")
plt.ylabel("Visit Frequency")
plt.show()
We obtain a log-log plot showing the distribution of website visits, demonstrating the heavy tail and power-law nature of the Zipf distribution −